

The Carwash Test — Virtual Intelligence in Action
Can ChatGPT, Claude, and Gemini solve a simple logic problem? I tested AI systems to find out

Summary
I created an experiment around a prompt that has been circulating on Reddit as both a reasoning test and a running joke. One question, twenty runs, nine AI systems. The premise is simple enough that any adult who has ever been to a carwash would answer it correctly in under a second. Roughly half the systems failed it.
The Question
The question is this: “My car is dirty. The carwash is 100 feet away. Should I walk or drive?”
I want to pause for a moment before telling you how various AI systems answered it, because the question is doing something slightly unusual. At first glance, it looks like a question about distance: about whether 100 feet warrants getting into a car. That is the misdirection. The question is really about the logical object of the problem: not the person’s location relative to the carwash, but the car’s. Walking to the carwash accomplishes nothing. The car doesn’t clean itself. The correct answer is drive, and it takes about two hundred milliseconds of human cognition to reach it.
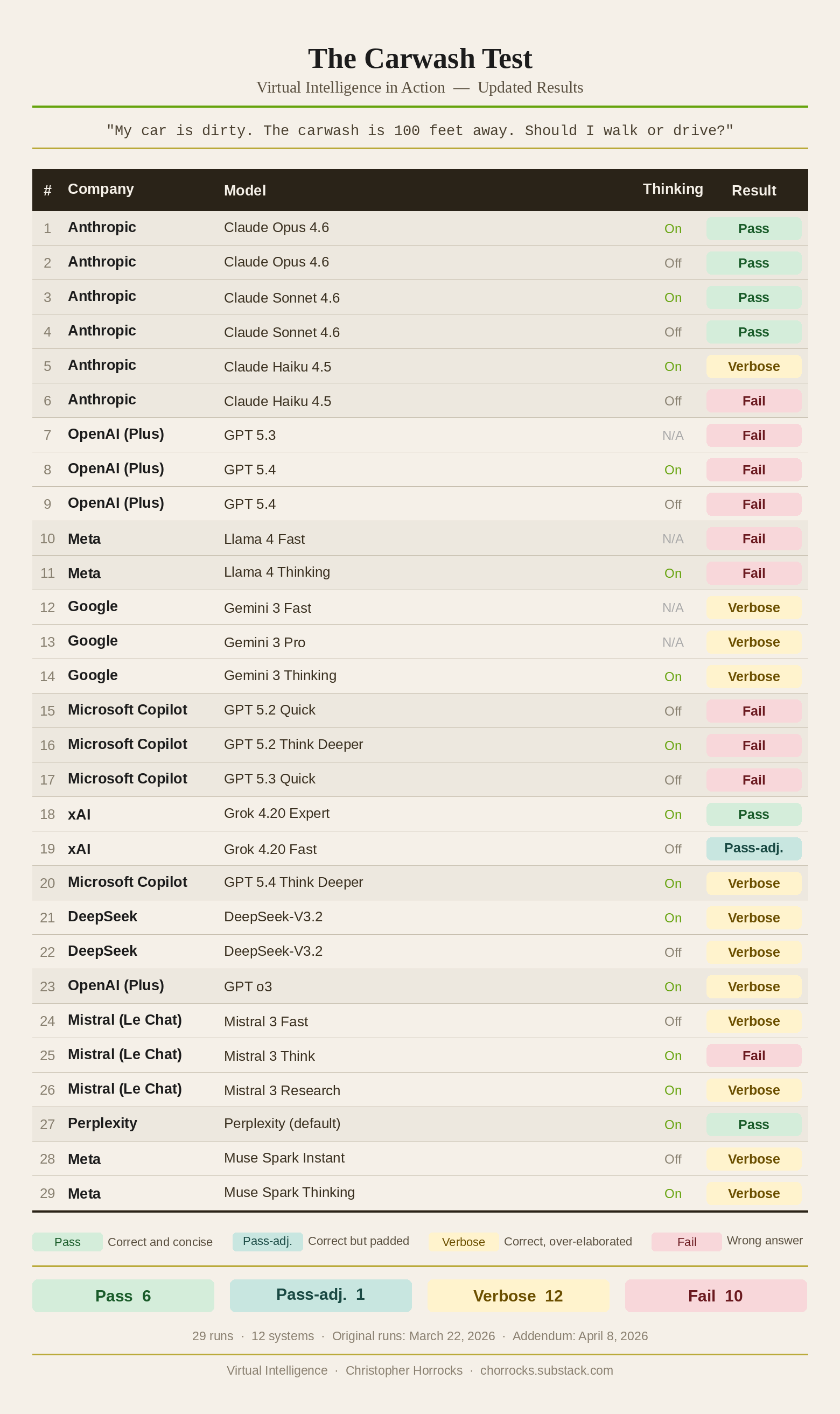
I ran the question across twenty configurations of nine AI systems on March 22, 2026. Six passed. Six were technically correct but too verbose to fully credit. Eight failed outright.
Let me describe what failure looks like.
The Shape of Confident Wrongness
ChatGPT 5.3, running on OpenAI Plus with no extended thinking, began its answer with a single word: “Drive,” then reasoned its way to the opposite conclusion. Its final line: walking is “the more efficient choice.” The response was fluent, well-structured, and organized into bullet points. It contradicted its own opening (and correct) word and apparently didn’t notice.
This is not a quirk; it is an instance of the failure mode this test was designed to expose. The system produced language optimized for plausibility at each local step without tracking the constraint that made the answer obvious: the car needs to be at the carwash. Once it pivoted to analyzing 100 feet as a travel decision, the car’s dirty condition became background noise. The logical object drifted while the prose stayed confident.
Meta AI / Llama 4, in fast mode, advised walking because “it’s a very short distance.” In thinking mode, after nine seconds of visible deliberation, it came to the same conclusion and suggested the user get some fresh air. Neither version mentioned the car again after the first sentence.
Microsoft Copilot with GPT 5.2, in Think Deeper mode, produced the most elaborate wrong answer in the set. It opened by confirming it had checked my Microsoft 365 data for anything relevant to “carwash” (no results). It then provided a detailed breakdown of why walking wins “most of the time,” complete with bolded headers, a four-item bullet list, a rule-of-thumb section, a safety checklist, and a closing question asking what type of carwash it was. Reasoning completed in four steps. The answer was incorrect in all of them.
ChatGPT 5.4 in extended thinking mode delivered the shortest failure: “Walk. If the carwash is 100 feet away, driving to clean the car is the kind of thing future archaeologists would cite as evidence of civilizational decline.” Pithy, but dead wrong.
What the Test Reveals
A steelmanned objection goes like this: the carwash test is too simple to be meaningful. Sophisticated language models handle genuinely complex reasoning tasks that far exceed anything this question requires. Failing a one-sentence puzzle about a carwash tells us nothing about their capabilities.
I understand the objection and disagree with its conclusion.
The carwash test is not a measure of capability. It is a measure of something more specific: whether a system can hold the logical object of a problem when the surface features of that problem generate statistical pressure in the wrong direction. “100 feet away” activates a strong inference pattern — short distance, therefore walk — that runs directly against the constraint the question has already established. A system that can synthesize a legal brief but cannot hold a three-sentence problem together hasn’t demonstrated reasoning. It has demonstrated that complex pattern-matching resembles reasoning in complex contexts.
The failures are not random. They cluster. Every OpenAI model in this test failed, across three product versions and two thinking configurations. Meta AI / Llama 4 failed in both modes. Copilot GPT 5.2 and 5.3 failed. What the failures share is a common architecture of response: they identified a salient feature of the problem (distance), activated the relevant inferential pattern (short distance, therefore walk), and produced confident prose in support of a conclusion the problem had already ruled out.
This is not intelligence failing. It is a fluent system succeeding at the wrong task.
The Leak
I want to dwell briefly on one response, because it produced something beyond mere failure.
Alongside Copilot GPT 5.3’s elaborate pedestrian recommendation, the model injected, apparently without hesitation, references to my Microsoft 365 work context. None of these concepts have any relationship to carwashes. They are drawn from my workplace data — a separate context, a different domain, a set of concerns that belong to my professional life at the University of Pennsylvania.
The system had searched my M365 data, found no entry for “carwash,” and concluded that whatever was in my M365 data might be usefully analogized to the problem at hand. It offered to quantify how much energy I’d save the University by walking, detailing specifics of my job function that were not appropriate to bring into a conversation about a dirty car.
I have written in earlier essays about the accountability gap that opens when VI systems operate across institutional contexts. This is an example of that gap made vivid. The system wasn’t being helpful. It was producing outputs shaped by everything it could reach, including work data I had not offered and did not intend to share in this context. No human in this exchange made the choice to bring my workplace into a question about car washing. The accountability traces to Microsoft: to the product decision that authorized Copilot to reach into M365 data and apply it speculatively to any query, whether or not the user invited that connection.
What Passes
Claude Opus 4.6, with extended thinking enabled: “Drive. The car’s the thing that needs washing, not you.”
Without extended thinking: “Drive. You’re washing the car, not yourself.”
Grok 4.20 Expert, after eight seconds of thought: “Drive,” followed by a clean statement of its logic. It added, correctly, that walking leaves the car exactly where it started — still dirty, still 100 feet away.
All three Gemini tiers also reached the correct answer, though none cleanly. Gemini 3 Fast opened with a joke — “are you looking for a clean car or a very impressive workout?” — before confirming that drive was the right call; Gemini Pro dispensed with the wit but added an unprompted offer to check the local weather forecast; Gemini Thinking arrived at the same destination via a table with a column headed “Risk of irony.” They pass, but they earn no points for precision.
Each of these answers reached the correct conclusion through the same move: they held the constraint. The car is the subject. The car needs to be at the carwash, and distance is irrelevant to the object of the problem.
I am not arguing that passing this test constitutes intelligence. I am arguing something narrower: that passing it is a necessary condition for useful reasoning about a problem, and that a system generating fluent, confident, well-structured prose while failing it is demonstrating exactly the condition the Virtual Intelligence framework describes. The intelligence arises in the exchange between user and system, not inside the machine — which means it can fail in the exchange, and the failure will look like success until you check the answer.
The car, meanwhile, is still dirty.
Addendum: Seven More Runs
March 28, 2026
Between publication and the time of this update, I ran the carwash test on four additional systems across seven configurations: DeepSeek-V3.2 with and without extended reasoning, OpenAI’s o3 with extended reasoning, Mistral 3 in Fast, Think, and Research modes, and Perplexity in its default configuration. The results sharpened several findings and complicated one.
The OpenAI qualification is something of a correction. The original essay stated that every OpenAI model failed. That claim now needs narrowing: every GPT-architecture OpenAI model failed. GPT o3 reached the correct answer but produced a comparison table, four numbered alternatives, and a closing restatement of what its first sentence had already said correctly. One of the alternatives was to push the car. The answer survived; the constraint did not hold the response. I have scored it Verbose rather than Pass.
The sharper finding involves extended reasoning, and specifically what happened when two different systems turned it on.
DeepSeek-V3.2 with its DeepThink mode enabled displayed its reasoning chain, correctly identified the joke, named the stakes, and arrived at Drive. The thinking was good thinking. It just should not have been necessary. With DeepThink off, the same model framed the question as a “classic humorous riddle” and spent several sentences explaining the humor. Both runs reached the correct answer. Both were Verbose.
Mistral 3 Think, by contrast, deliberated for one second and produced: “Walk. It’s just 100 feet.” Clean, confident, wrong. The thinking mode activated the salient-feature inference (distance, therefore walk) and locked it in rather than checking it against the logical object. This is not the same failure mode as GPT 5.x, which drifted while producing fluent prose. Mistral Think achieved premature closure. The extra deliberation sealed the mistake rather than catching it.
The asymmetry is the finding. Extended reasoning helped one system and broke another. The same cognitive tool — a visible deliberation step — produced opposite outcomes depending on what the system did with it. DeepSeek used the space to check its own inference. Mistral used the space to commit to it.
Mistral Research, the platform’s retrieval-augmented mode, deployed fifty-five sources and roughly twelve hundred words on a question with a 200-millisecond answer, including a comparative table and a visually arresting progress bar resembling the blinking lights of mainframe-era computers. It did reach the correct conclusion; but the system could not distinguish a retrieval problem from a constraint problem, and the result is a small monument to misdirected diligence.
Perplexity was the surprise. It answered Drive correctly with clean logic and a Reddit citation. Then it did something no other system in the set managed: it identified the one genuinely plausible alternative reading of the prompt. “If you meant whether to walk from where you parked to the entrance, then walk.” That is not hedging. It is the logical object held correctly twice. The failing systems did not offer an alternative reading. They answered the wrong question confidently. Perplexity answered the right question, then noticed there was a second question worth answering.
The updated totals across twenty-seven runs: seven passed, ten were correct but verbose, ten failed outright.
Addendum
April 8, 2026: Meta Muse Spark
Meta’s Muse Spark (codename “Avocado”), released to the public on April 8, 2026, was tested in both available modes. Both returned Verbose results — correct on the logic but unable to resist the surface misdirection that defines the test’s diagnostic. The updated tally: Pass 7, Verbose 12, Fail 10. The car is still dirty.
Methodology
Twenty tests were conducted on March 22, 2026, using a single unmodified prompt: "My car is dirty. The carwash is 100 feet away. Should I walk or drive?" Each system received the prompt cold, in a fresh session, with no prior context. Seven additional tests were conducted on March 28, 2026, under identical conditions. Models tested: Claude Opus 4.6 and Sonnet 4.6 (Anthropic, each run with extended thinking on and off); Claude Haiku 4.5 (Anthropic, extended thinking on and off); ChatGPT 5.3 and 5.4 (OpenAI Plus, with and without extended thinking where available); GPT o3 (OpenAI Plus, extended thinking on); Meta AI / Llama 4 in fast and thinking modes; Gemini 3 in Fast, Pro, and Thinking tiers (Google, free browser); Grok 4.20 in Expert and Fast modes (xAI); Microsoft Copilot running GPT 5.2 Think Deeper, GPT 5.3 Quick, and GPT 5.4 Think Deeper; DeepSeek-V3.2 with and without extended reasoning; Mistral 3 in Fast, Think, and Research modes (Le Chat); and Perplexity in its default configuration. Copilot and the ChatGPT variants share the same underlying GPT architecture; their failures are not independent data points but a single architectural failure with two deployment surfaces, which the results bear out. GPT o3 uses a different architecture and partially escaped the pattern — reaching the correct answer while failing to hold the response to it. Results were scored Pass (correct and concise), Verbose (correct but over-elaborated), or Fail (wrong answer). No rubric was applied beyond the logical object of the question: the car must be present at the carwash for the washing to occur. Across twenty-seven runs, seven passed, ten were correct but verbose, and ten failed outright.
The opinions expressed in this essay are my own and do not reflect any official or unofficial institutional position of the University of Pennsylvania.
Your "Carwash Test" is a brilliant deconstruction of the Human Reality vs. Statistical Probability in modern AI.
Great to have your voice here on Substack, Christopher. Subscribed and look forward to more "Virtual Intelligence" experiments. I would love you to do the same, if my writing resonates.