

The Carwash Test, Part II
New results from a simple AI reasoning test that most models still fail — including GPT, Claude, Gemini, and nine others

Introduction
When the Carwash Test was first published in March, the dataset stood at twenty runs across nine systems. The time has come to revisit previously tested systems, to add new ones, and to extend the test to non-U.S. models.
The test sits in a small and unfashionable corner of AI capability evaluation. Most benchmarks reward something visible at a glance: a working application produced from a single prompt, say, or an image of a chess board with the pieces in valid mid-game positions. The running code or the rendered scene does the work; the evaluator does not need to follow an argument in prose to be impressed.
What such demonstrations do not measure is whether the system can hold the logical object of a query against statistical pressure pushing in the wrong direction. A model can compose a coherent novel scene from a paragraph of instructions and still fail to notice that a car must be at the carwash to be washed. The same is true at the visual end: image models that have learned to render five fingers reliably have not become better at sequencing time, preserving anatomical integrity, or representing physical possibility. These are different failure modes. Catching one tells us nothing about the other.
The Mechanism
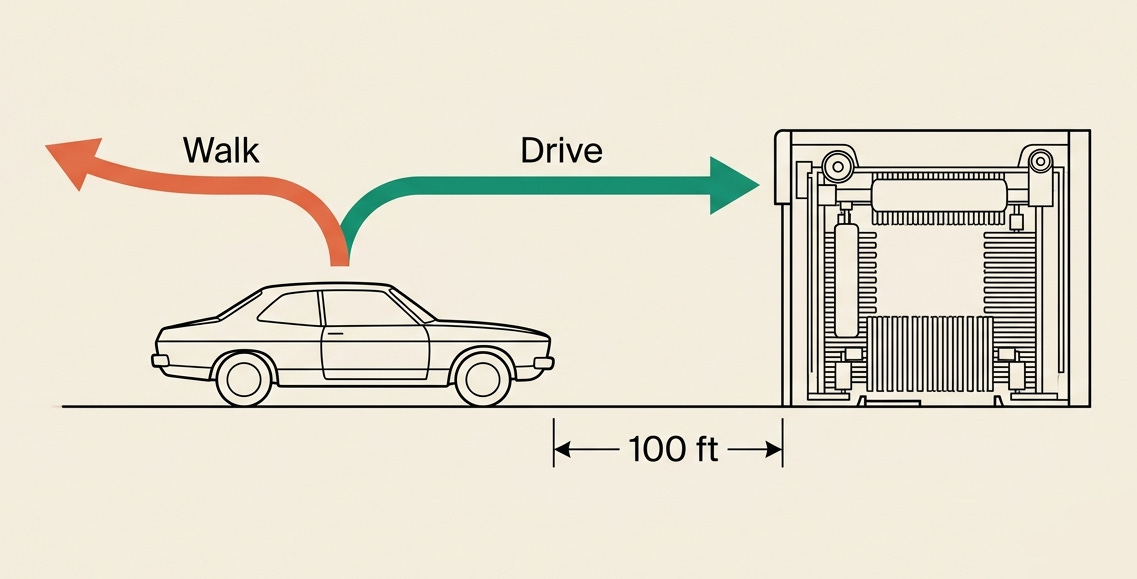
The test is a single question: “My car is dirty. The carwash is 100 feet away. Should I walk or drive?” The answer is drive. The car needs to be at the carwash. Walking gets you there; it does not get the car there.
This 70-character prompt activates two competing forces within the system that encounters it.
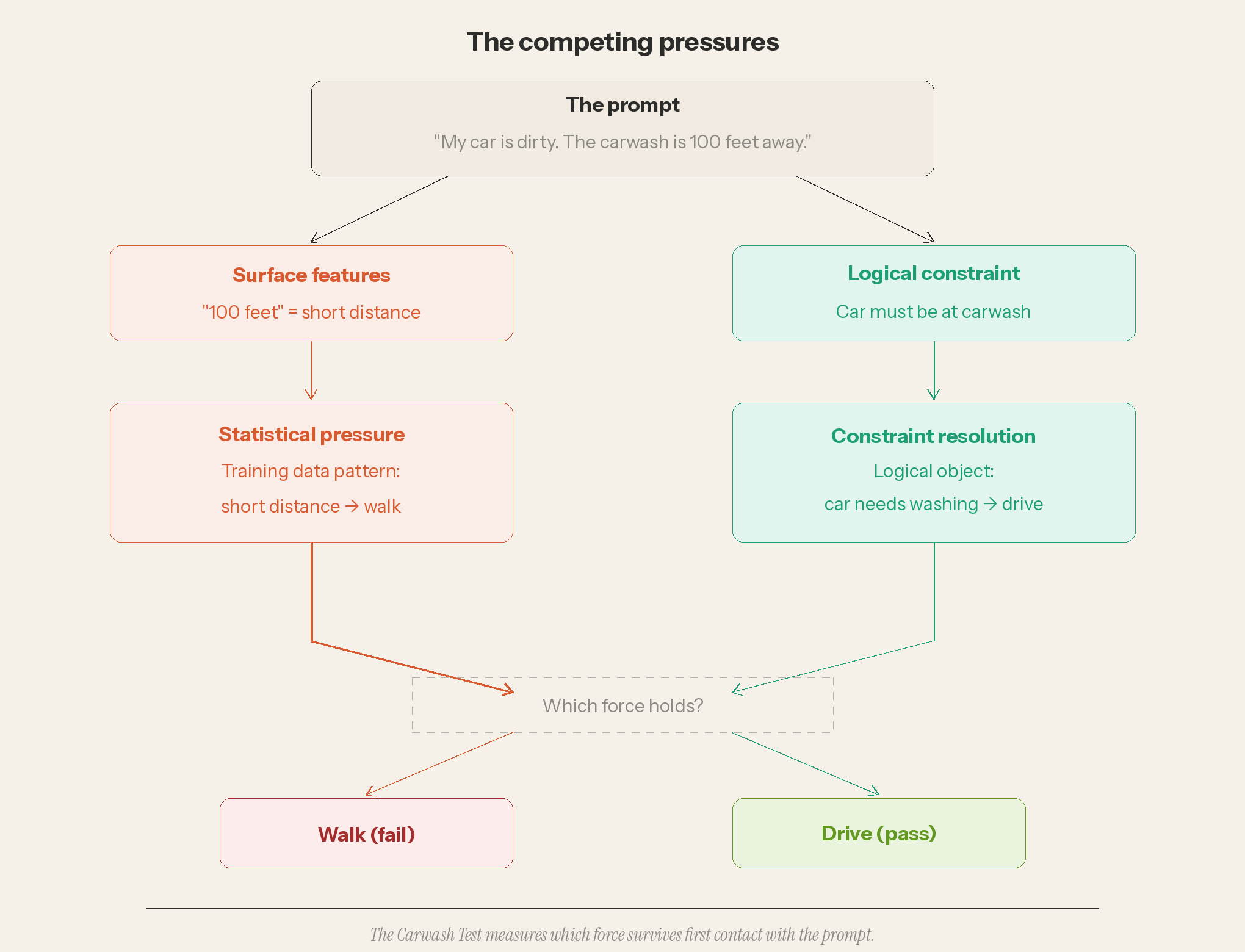
The surface features of the prompt — “100 feet,” a distance the training data overwhelmingly associates with walking — push the system toward the wrong answer. The logical constraint — the car must be at the carwash to be washed — pushes toward the correct one. The test measures which force survives first contact with the prompt. In the March dataset, the surface features pushing the incorrect answer won more often than not.
There is a second mechanism worth showing before the new results arrive. In some systems, engaging the reasoning toggle makes the output worse, not better.
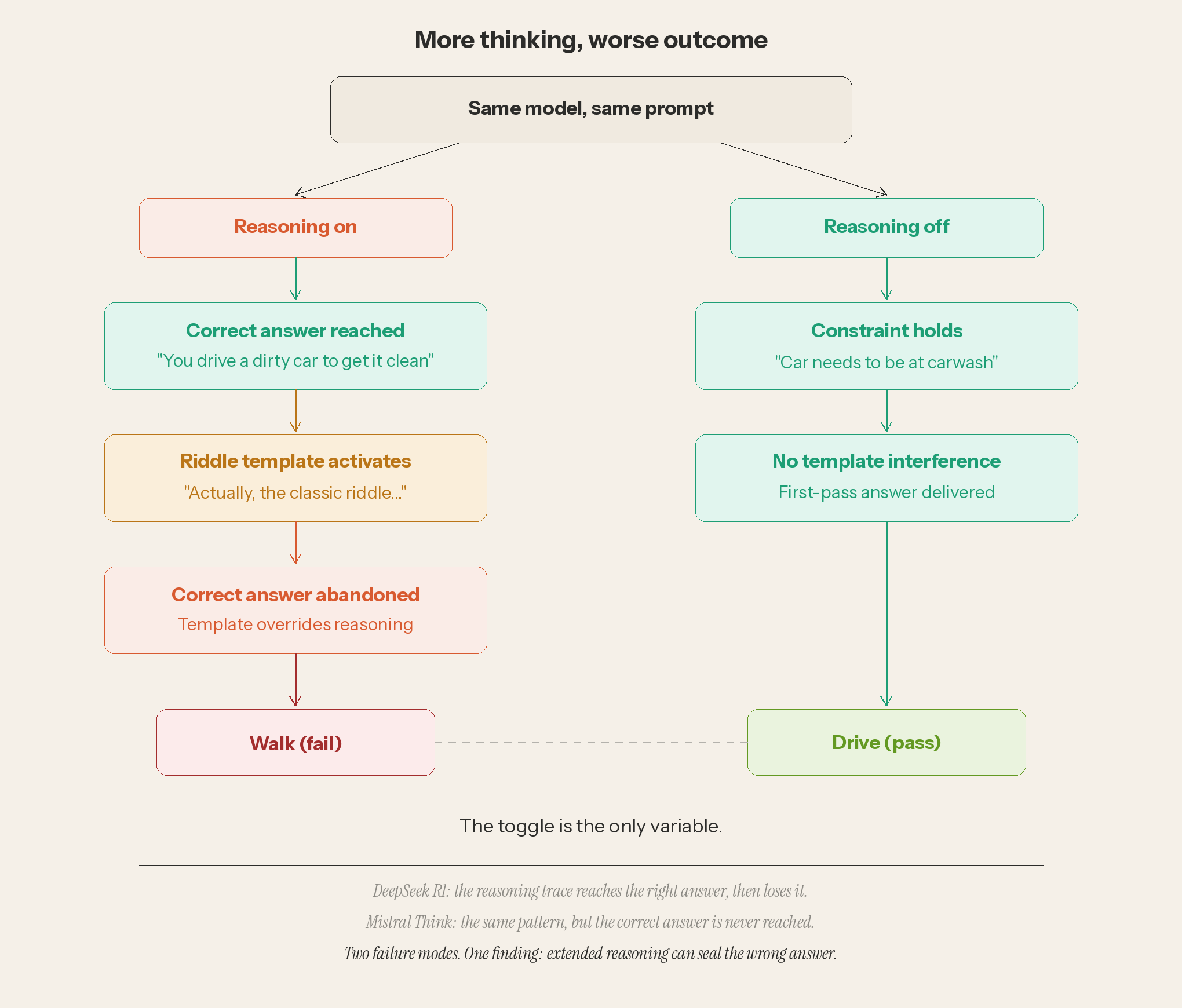
A past run of the test on DeepSeek R1 with thinking enabled was the cleanest specimen. Its reasoning trace, captured on April 27, shows the model reaching the correct answer. A “riddle” template then activates and overrides it, leading to “walk”. The model had the right answer and released it. Mistral Think showed the same pattern through a different mechanism: the wrong inference fired within one second and sealed the outcome before the constraint could assert itself. The first model lost the answer; the second never found it. In both cases, extended reasoning was the variable that produced the wrong result. (DeepSeek R1 Transcript)
What Changed Since March
The May 3 batch expanded the test across three dimensions.
Scale: 51 new runs brought the dataset from 38 to 89 entries. Vendor coverage grew from nine model families to twelve, spanning four jurisdictions. Three international models entered the dataset for the first time: Qwen from Alibaba, Kimi from Moonshot AI, and Lumo from Proton. (Aleph Alpha was investigated and excluded — the company has pivoted to enterprise-only deployment, and no public-facing chat interface remains.)
Product surfaces shifted beneath the test. Anthropic reverted Opus 4.6 to its Extended Thinking On/Off toggle (having briefly replaced it with an Adaptive mode). xAI released Grok 4.3 with a new three-state picker: Auto, Fast, Expert. Mistral substituted Medium 3.5 as the default model behind Le Chat. Meta added Contemplating, a multi-chain parallel reasoning mode, to its Muse Spark interface.
Microsoft Copilot was included as a special case. The original Copilot runs had been contaminated by M365 workspace retrieval — the product surface pulling external context into the response. The May 3 batch used an isolation prompt to suppress retrieval and test the underlying models through the wrapper: “Do not search the web, do not search my files or documents, and do not use any workspace or conversation context. Answer the following question using only your own reasoning.” The canonical carwash prompt followed. This is a different prompt than the one every other vendor received, and the Copilot results are best read as a distinct sub-study.
The methodology was otherwise unchanged. Single-shot, fresh chat, no follow-up turns, first response is the answer. Same rubric: Pass, Pass-adjacent, Verbose, Fail.
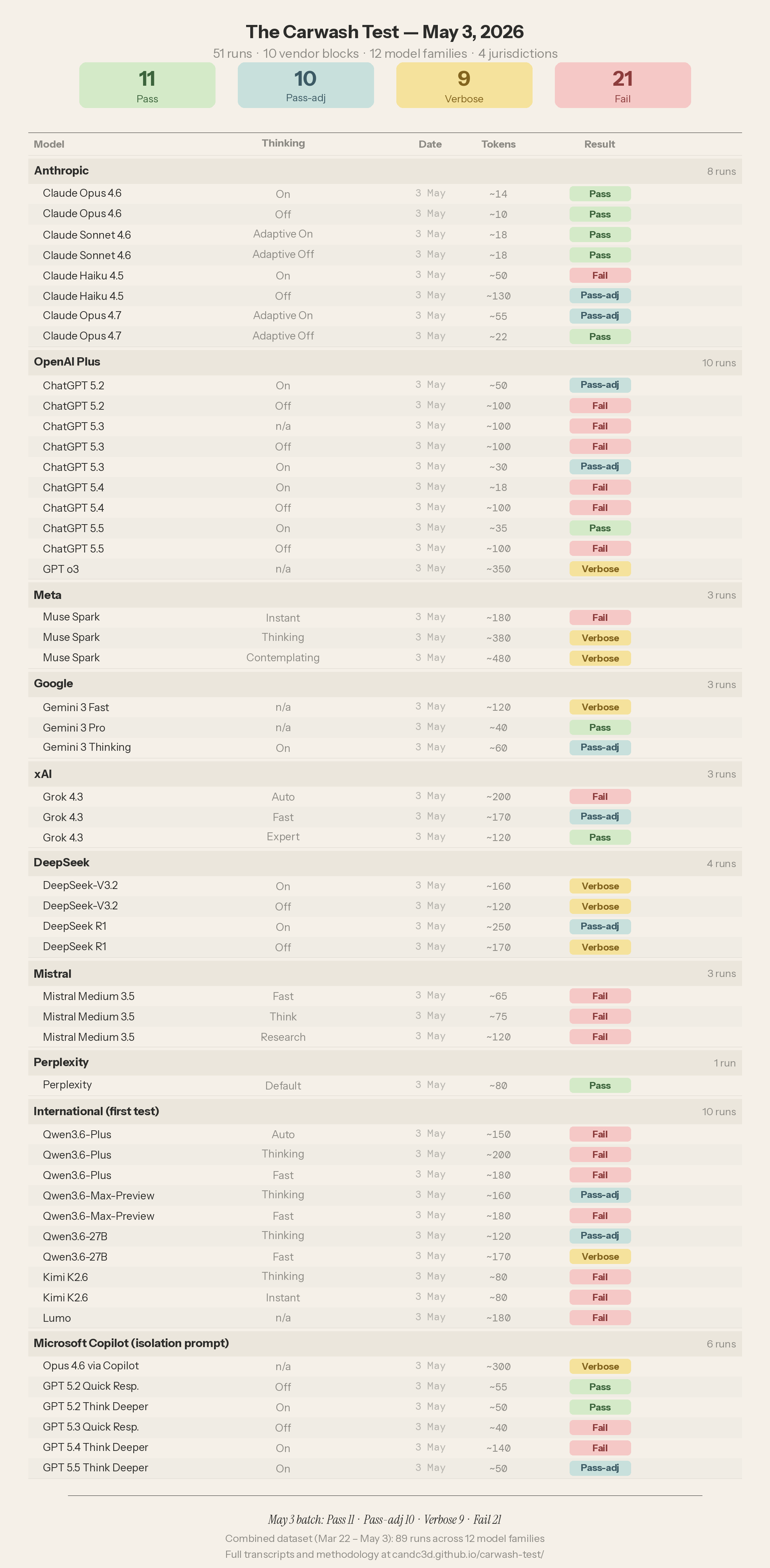
The Results
Fifty-one runs scored. Pass: 11, Pass-adjacent: 10, Verbose: 9, Fail: 21. Six findings emerged from the test runs.
The Identical-Text Finding
Four GPT models — 5.2, 5.3, 5.4, and 5.5 — produce byte-identical wrong answers when thinking is disabled. It is the same text, word for word: “Honestly, driving 100 feet would be more trouble than it’s worth. At that distance, walking is the clear winner.” This was confirmed by a live retest on a fresh account.
This is not four independent failures of reasoning. It is one shared response path producing one shared wrong answer, distributed across four model names that the consumer interface presents as distinct products. A subscriber who switches from GPT 5.5 to GPT 5.2 thinking they are getting a different perspective is getting the same faulty reasoning.
Every GPT model fails when thinking is off. Every model except 5.4 passes when thinking is on. The toggle is the only variable. GPT 5.4 fails in both states — pithy, confident, and wrong: “Walk. Driving 100 feet to a carwash because the car is dirty is how a joke starts.” In March, the same model produced a similar quip: “Walking to clean the car is the kind of thing future archaeologists would cite as evidence of civilizational decline.” GPT 5.4 is the worst-performing model in the entire OpenAI family across both snapshots.
The consumer cost: identical wrong answers at roughly 100 tokens each, delivered five times to anyone who tests the full model picker without enabling reasoning. (GPT Transcripts)
DeepSeek R1 Self-Corrected
The most significant longitudinal finding in the May 3 batch is the simplest to see: the April DeepSeek R1 failure is gone.
In April, DeepSeek R1 with thinking enabled was the cleanest specimen of mid-reasoning template capture. The reasoning trace showed the model reaching the correct answer, then a riddle template activating, then the correct answer being abandoned. In May, the model still recognizes the prompt as a “humorous or paradoxical riddle”, but the correct answer survives. The reasoning chain that previously derailed now holds.
DeepSeek updated the model between snapshots.
It’s important to be precise about what this shows and what it does not. The first test resulted in failure. The vendor shipped an update sometime afterward, and the failure is no longer present. Whether DeepSeek fixed it because of the Carwash Test or for entirely unrelated reasons is unknown and I make no claim either way. The longitudinal record is the point. The test was designed to measure change across time, and R1 is the first model in the dataset where the change runs in the right direction. Something in the model’s updated weights or inference logic now resists the riddle template that previously captured the output.
The R1 reasoning trace remains the most diagnostic artifact in the dataset. It is the one entry where the mechanism is visible on the page.
Adaptive Autoselection Fails Across Vendors
Three vendors now ship consumer interfaces where the model decides whether and how much to reason: Anthropic’s Adaptive On, xAI’s Grok 4.3 Auto, and Alibaba’s Qwen3.6-Plus Auto.
Anthropic’s Adaptive On passes cleanly across all three models it was tested on: Opus 4.6, Sonnet 4.6, Opus 4.7. Grok 4.3 Auto fails. Grok 4.3 Fast passes. Grok 4.3 Expert, after twenty-three seconds of deliberation, passes cleanly. Qwen3.6-Plus Auto fails. Qwen3.6-Plus Thinking fails. Qwen3.6-Plus Fast fails.
Two of three adaptive implementations fail on this prompt. The one that passes, Anthropic Claude, is also the vendor that has been tested the most on this specific prompt. This confound is worth acknowledging. Whether Anthropic’s Adaptive mode passes because its autoselection logic is better, or because the underlying models have been exposed to the Carwash question in ways that influence their training is a question I cannot answer from outside the weights.
The Grok result is especially instructive. The default mode — Auto, the one consumers encounter when they open the product in their browser — thought for two seconds and got it wrong. Fast mode, with four seconds of thought, got it right. Expert mode, with twenty-three seconds, got it most right. More deliberation produced better results, but the model’s own judgment about how much to deliberate was the failure point. The default selection can be the wrong choice.
New Mistral Model Made Things Worse
Mistral Medium 3.5 replaced Mistral 3 as the default model in Le Chat sometime in late April. The Carwash Test caught the change in real time: the model behind the interface is different, and it performs worse.
In March, Mistral 3 produced correct answers in two of three modes. Fast mode was Verbose but correct. Research mode produced a 2,400-token academic report — complete with a 56-source bibliography — that arrived at the right answer through an extraordinary amount of analysis. Think mode failed. The model was two-for-three.
In May, Mistral Medium 3.5 produced zero correct answers across three modes. Fast mode fails. Think mode fails with inverted logic: “you won’t get your clean car dirty again by driving it there,” implying the car is currently clean. Research mode asks four clarifying questions and declines to commit to an answer.
A newer model performing worse on the same diagnostic is a finding about what model updates optimize for. The update optimized for something; it did not optimize for holding the logical object of a simple problem against statistical pressure. That is not unusual — no benchmark I am aware of measures it — but the Carwash Test does, and the regression is visible in the data. (Mistral Transcripts)
The Wrapper Changes the Answer
Microsoft Copilot wraps models from other vendors in its own product layer, with its own governance regime, its own retrieval surfaces, and its own tool ecosystem. The May 3 batch tested what happens when those retrieval surfaces are suppressed and the underlying models are left to reason on their own.
The sharpest finding: GPT 5.2 with thinking off fails on OpenAI Plus and passes on Microsoft Copilot. On Plus, 5.2 Off produces the identical-text failure shared by every GPT thinking-off model. On Copilot with the isolation prompt, 5.2 Off produces a clean pass: “Drive. The goal is to clean the car, not to travel the 100 feet efficiently.”
The isolation prompt breaks whatever cached or default response path the Plus surface activates when thinking is disabled.
Claude Opus 4.6 tells a related but different story. The model passes on both surfaces — Anthropic and Copilot — but the wrapper inflates the response from fourteen tokens on Anthropic’s surface to roughly three hundred tokens on Copilot. Microsoft’s governance layer changes the response shape without changing the answer.
The Copilot wrapper, or any other wrapper, is a variable that contributes to what determines the answer. It must be considered when deploying any such system. The major vendor model being deployed through such a wrapper is not quite the same as the one you would interact with if you contracted directly with the vendor.
For consumers and businesses paying per token, the correct answer through Microsoft Copilot costs twenty times what the same correct answer costs through Anthropic. (Copilot Transcripts)
Cross-Jurisdictional Failure Clustering
The international block — Qwen from Alibaba, Kimi from Moonshot AI, Lumo from Proton — was included to test whether the failure pattern observed across US and French vendors would hold in Chinese and Swiss systems trained on different data, deployed under different regulatory frameworks, and serving different consumer markets.
The results show that the pattern of failure holds across these new entrants. Seven of ten of the newcomer runs failed. The failure rate of 70% is the highest of any block in the dataset. The failure modes are the same: “100 feet” activates “short distance” activates “walk.” The surface features override the logical object exactly as they do in every other jurisdiction.
Qwen3.6-Plus fails all three modes: Auto, Thinking, and Fast. It is the only model family in the entire dataset where every tested configuration fails. Qwen’s smaller models do better: Max-Preview splits on the toggle (Thinking passes, Fast fails), and the 27B parameter model passes in both modes. The smallest Qwen model outperforms the largest on this test.
Kimi fails both modes. Lumo fails and suggests pushing the car as an alternative to driving it.
The finding is structural across models and national borders. The Carwash Test is not measuring a US-vendor-specific behavior. It is not measuring something introduced by English-language training data alone. It is measuring the way large language models handle competing inference patterns when surface features and logical constraints point in opposite directions. The pattern is the same in Shanghai, Geneva, and San Francisco.

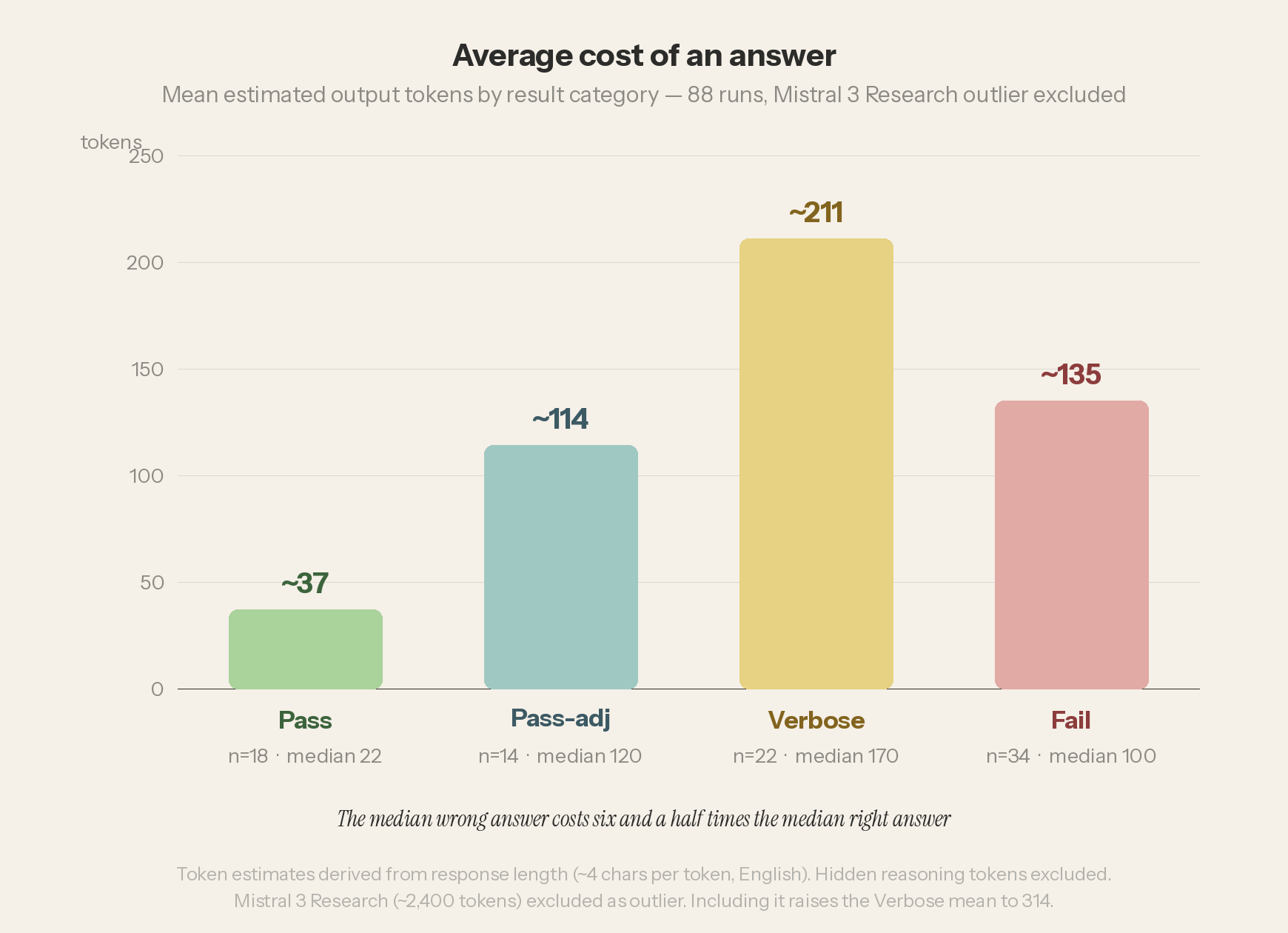
What It Costs
The diagram above tells us something about what all of this costs. The proportional bar at the bottom shows what has not changed across three snapshots and a grand total of eighty-nine runs: two-thirds of all consumer-interface responses cost more than the answer should have. Only twenty percent of runs — those in the Pass category — resolved the constraint cleanly and stopped.
The token ranges show what that distribution looks like in practice. The median Pass costs 20 tokens. The median Fail costs 130 tokens. The median wrong answer is six and a half times more expensive than the median right answer. The consumer is paying more for an answer that’s dead wrong.
The extremes are instructive. The cheapest fail in the dataset is GPT 5.4 with thinking on: “Walk. Driving 100 feet to a carwash because the car is dirty is how a joke starts.” It cost eighteen tokens. The most expensive correct answer in the total set is Mistral 3 Research from March: roughly 2,400 tokens, including a 56-source bibliography, to arrive at a conclusion a child could state in four words or less. The 2,400-token response cost 133 times what the 18-token response cost, and only the former is correct.
For institutional purchasers — IT directors, procurement officers, anyone responsible for enterprise AI deployments — this cost finding scales with the number of licensed seats at their institution. Token cost is a line item, no matter how the tokens are sold. A model that produces six and a half times the output to reach the wrong answer is a cost multiplied across thousands of employees multiplied by hundreds of queries per day, every day the contract runs.
Wrong answers cost more than the tokens. Every token spent on a wrong answer is lost. The computation expended, the electricity used, the waste heat generated, and the water used to cool the system are utterly wasted.
The Dataset
The combined dataset now stands at eighty-nine runs: Pass 18, Pass-adjacent 14, Verbose 23, Fail 34. Twelve model families. Four jurisdictions. Three snapshots — March 22, the April addenda, and May 3. Full transcripts and methodology are published at candc3d.github.io/carwash-test/.
The Reddit r/ClaudeAI community independently replicated the test with similar findings. The test has been conducted entirely through consumer chat interfaces, using the same product surfaces available to any subscriber. Nothing about the methodology requires API access, special tooling, or institutional resources. The prompt is seventeen words. The test is free.
What Comes Next
The dataset will be extended in July with the next generation of frontier models. New prompt variants will test whether the surface-pressure finding generalizes beyond the “100 feet” construction — whether other distances, other surface features, other competing patterns produce the same split between statistical pressure and logical constraint.
The Carwash Test is both a series of snapshots across time and a longitudinal instrument. The dataset will continue to grow until the number of “pass” scores makes it irrelevant. Everything seen during testing indicates that time is not coming soon.
The car is still dirty.
The Prompts & Website
Canonical Prompt
My car is dirty. The carwash is 100 feet away. Should I walk or drive?Restraint Prompt (for systems that search personal and work context for answers, such as Copilot)
Do not search the web, do not search my files or documents, and do not use any workspace or conversation context. Answer the following question using only your own reasoning. Here is the question: My car is dirty. The carwash is 100 feet away. Should I walk or drive?Full results of all runs conducted since this experiment began, including transcripts, can be found at candc3d.github.io/carwash-test/. The site will be updated as new results arrive.
Footnotes
Christopher Horrocks, “The Carwash Test — Virtual Intelligence in Action,” Virtual Intelligence, chorrocks.substack.com, March 27, 2026 (consolidated republication April 24, 2026).
The Reddit r/ClaudeAI replication thread, r/ClaudeAI/comments/1sfw9b5/something_happened_to_opus_46s_reasoning_effort/, April 8–9, 2026 (560+ comments; community independently tested the prompt across multiple systems and confirmed the failure pattern).
xAI, Grok 4.3 release notes, grok.com/release-notes, April 30, 2026. Grok 4.3 replaced Grok 4.20 and introduced the Auto/Fast/Expert picker.
Mistral AI, “Vibe, Remote Agents, Mistral Medium 3.5,” mistral.ai/news/vibe-remote-agents-mistral-medium-3-5, late April 2026. Medium 3.5 became the default model in Le Chat.
Full dataset and transcripts: candc3d.github.io/carwash-test/.
The opinions expressed are my own and do not reflect any official or unofficial institutional position of the University of Pennsylvania.
The author holds no financial interest in, and receives no compensation from, any AI or technology firm.